所有浏览器都有自己的缓存机制,它们通过将资源缓存到本地,借此加速用户访问客户端的速度,减少服务器压力。
近期发布的 chrome 86 启用了新的浏览器缓存策略,我们一起来看看它是什么,为什么出现,以及带来的影响吧!
在介绍它之前,我们先来看看旧的缓存策略。
旧缓存策略-单键储存
chrome 86 版本以前,引用/储存缓存的键名是资源的 URL。如图:
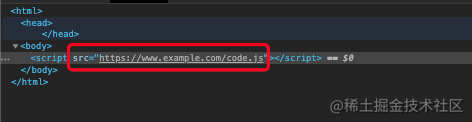
也就是说,如果有其他任何网站引用到了同个 URL的资源,浏览器会先去缓存里面查询有无资源,有则加载本地资源,无则远程请求。
新缓存策略-缓存分区(Cache partitioning)
从 chrome 86 版本开始,启用了新的缓存策略-缓存分区。
从前端开发者的角度出发,我得知这个消息的第一反应是:啊!是 chrome 派来解决用户使用缓存里的旧版本,而前端资源已经更新导致的版本一致性问题吧?毕竟本人遇到的浏览器缓存导致唯一问题就是这个,殊不知不同的角度有不同的困惑,缓存分区,主要是解决谁的困惑呢?
为什么要做缓存分区
其实旧的缓存机制一直表现都挺好的,兢兢业业,奈何人算不如天算。广告商和分析公司借此可以在用户不知情的情况下跟踪用户行为,攻击者也可以拿到你的某些网站身份信息。
具体包括:
判断用户是否访问过特定网站
通过检索缓存是否具有特定于某站点的资源(脚本、图片、CSS等)来检测用户的浏览历史记录。例如:通过对缓存内容的查询了解你有哪些社交账号,利用你的帐户名称滥用你的个人信息。
跨站点搜索攻击:判断用户是否搜索过特定内容
存在一些概念的跨站点搜索攻击证据,这些概念利用了一些站点(gmail,google search,…)在搜索结果为空时加载特定图像的事实。通过打开选项卡并执行搜索,然后在缓存中检查该图像,攻击者可以检测搜索结果中是否存在任意字符串。
通过检索与搜索结果相关的图片缓存,判断用户是否搜索过特定内容。例如:
淘宝网在搜索结果为空时才会加载哭哭脸小二的图片,可以借此用户是否搜索。
购物网站
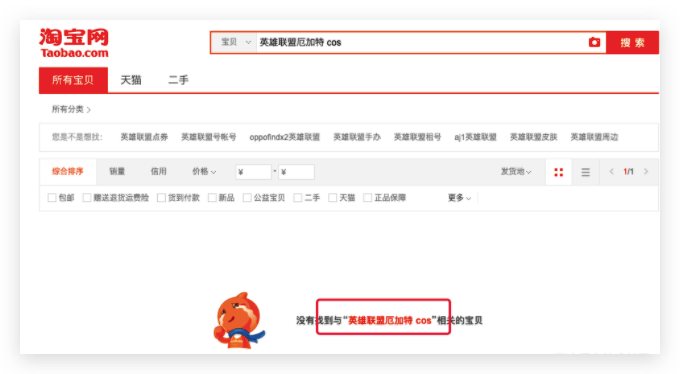
如果整块搜索结果是图片,图片中有搜索关键词的信息,那么甚至还可以获取用户的搜索关键字。
跨站跟踪:共享身份信息
使用 HTTP 缓存储存类似 Cookie 的身份信息,来进行跨站跟踪。
我们都知道,Cookie 是无法跨域访问的。
但实际上除了第一方 Cookie,还存在一种第三方 Cookie —— 广告商的 Cookie
这种 Cookie是由站点内的广告跟踪器记录的。广告跟踪器相当于嵌入原站点的另一个网站,于是你就有了两份 Cookie :
- 原站点的
Cookie,用于记住你的登陆。 - 广告商的
Cookie,用于记住你的身份。
通过第三方 Cookie,两家网站就可以共享同一个Cookie,共享用户的身份识别信息。
当然第三方 cookie 也有好处,例如你在淘宝登录了,去天猫就不需要再登录一次了。
怎么做缓存分区
可恶,为什么我的隐私在裸奔,想安安静静偷偷摸摸的上网,有那么难吗?
新的策略横空出世(实际上从 chrome 77 版本就一直在测试这个功能)新的 chrome 针对这些问题,做了哪些改变呢?
此前资源的存储键只有一个项,现在则包含三个项,分别为域名 (domain)、当前帧 (domain) 和网址 (URL)。
- 网页域名 (http://a.example)
- 资源的当前 iframe (http://c.example)
- 资源 URL (https://x.example/doge.png)
新旧策略对比图
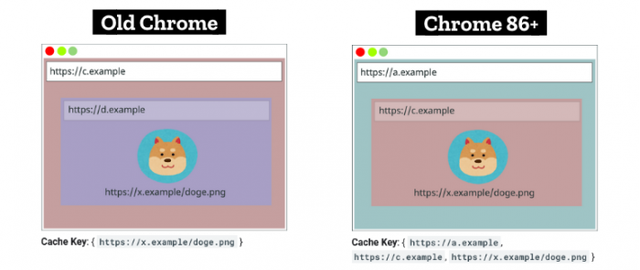
例如:
用户返回了 https://a.example ,但是图片是属于 iframe https://c.example 。
遇到这种情况,资源会不会从缓存里面读取呢?
答案是不会!因为不匹配 Cache Key 为 https://a.example , https://c.example ,以及https://x.example/doge.png 的资源,所以无法使用 https://c.example 里面的缓存。
使用缓存分区之后的变化
- 网站网络流量增加约 4%。 对具体影响什么参数感兴趣的可以戳这里
- 广告商想要从缓存入手跟踪用户变得更难。
总结
在网络隐私越来越重要的今天,chrome 为了保护用户选择牺牲一部分不易被察觉的体验,考虑到我们网络的速度以及电脑的配置也在一直升级,相信大多数用户会支持缓存分区。